はじめに
表記に一部誤りを含む曲名・アーティスト名を入力として、正しい名前を出力 or マッチ度を計算する関数を作る必要があったため、調査・実装など検討してみました。
レーベンシュタイン距離
レーベンシュタイン距離(レーベンシュタインきょり、英: Levenshtein distance)は、二つの文字列がどの程度異なっているかを示す距離の一種である。編集距離(へんしゅうきょり、英: edit distance)とも呼ばれる。具体的には、1文字の挿入・削除・置換によって、一方の文字列をもう一方の文字列に変形するのに必要な手順の最小回数として定義される[1]。名称は、1965年にこれを考案したロシアの学者ウラジーミル・レーベンシュタイン (露: Влади́мир Левенште́йн) にちなむ。
使ってみた
"L'Arc~en~Ciel"に対して、表記が一部誤った、もしくは全く違う文字列とのレーベンシュタイン距離ベースの類似度を出してみました。
L'Arc~en~Ciel L'Arc en Ciel 0.846 L'Arc~en~Ciel larc en ciel 0.538 L'Arc~en~Ciel larc 0.154 L'Arc~en~Ciel l'arc 0.231 L'Arc~en~Ciel janne da arc 0.000
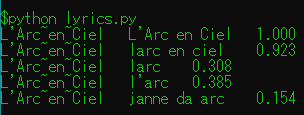
ここで、アーティスト名・曲名の検索を想定して、いくつか工夫をしてみました。
- 大文字・小文字は同じとする
- 記号・特殊文字は空白文字に変換する
L'Arc~en~Ciel L'Arc en Ciel 1.000 L'Arc~en~Ciel larc en ciel 0.923 L'Arc~en~Ciel larc 0.308 L'Arc~en~Ciel l'arc 0.385 L'Arc~en~Ciel janne da arc 0.154
工夫した方が、いい感じな結果になりました。
日本語を考慮した実用では、ひらがな、 カタカナ、ローマ字、漢字の対応関係・変換や、通名・愛称への対処など泥臭い処理が必要になると思います。
付録・実装
以下の記事を参考に実装しました。
編集距離(レーベンシュタイン距離)を理解し、実装する - Qiita
from functools import lru_cache def __ld(s1, s2): if not s1: return len(s2) if not s2: return len(s1) if s1[0] == s2[0]: return __ld(s1[1:], s2[1:]) l1 = __ld(s1, s2[1:]) l2 = __ld(s1[1:], s2) l3 = __ld(s1[1:], s2[1:]) return 1 + min(l1, l2, l3) def levenshtein_distance(s1, s2): return __ld(s1, s2) / max(len(s1), len(s2)) def levenshtein_similarity(s1, s2): return -levenshtein_distance(s1, s2) + 1