ポピュラー音楽では、楽曲の聞かせどころであるサビは楽曲の最も盛り上がる部分であり、その楽曲の印象に深くかかわります。
サビ検出には様々な手法がありますが、今回は実装が簡単な手法として音響特徴量を使ったサビ検出手法を実装・検証してみました。
サビ検出アルゴリズムの方針・実装
邦楽におけるサビは、楽曲で最も盛り上がる区間です。
また、1番、2番というように曲の中で何度も繰り返されます。
従って、以下のような仮説を立てることができます。
- 曲の冒頭や最後に存在する可能性が高い
- 音の短時間エネルギーが最も高い値となる
- 音色が煌びやかになる
これら3つの仮説に基づいてサビ検出の実装を行います。
仮説2, 3については、音の短時間のエネルギーを表すRMSと、音色の煌びやかさを表すスペクトル重心を使います。
それぞれ、Pythonの音楽分析モジュールであるLibROSA では、librosa.feature.rms(), librosa.feature.spectral_centroid()を使うことで簡単に算出することができます。
RMS, スペクトル重心の時系列データをそれぞれ正規化して足し合わすことで、サビらしさ特徴量時系列データとして扱います。
以上より、このサビらしさの特徴量時系列データ*1が最大値を取るところは、音のエネルギーが大きく煌びやかなのでサビである可能性が高いと考えられます。
ただし、仮説1を利用し、サビらしさの特徴量時系列データの先頭および末尾からいくつかのデータを除外することで検出精度を上げることができます。
以上を実装すると以下のようなコードになります。
filepath = "/path/to/audiofile.ext" sr = 44100 # オーディオファイルを信号データとして読み込み # 今回はモノラル信号(中央定位成分)を利用 y, sr = librosa.load(filepath, sr=sr, mono=True) # 特徴量算出用のパラメタ frame_length = 65536 # 特徴量を1つ算出するのに使うサンプル数 hop_length = 16384 # 何サンプルずらして特徴量を算出するかを決める変数 # RMS:短時間ごとのエネルギーの大きさを算出 rms = librosa.feature.rms(y=y, frame_length=frame_length, hop_length=hop_length)[0] rms /= np.max(rms) # [0.0. 1.0]に正規化 # スペクトル重心:短時間ごとの音色の煌びやかさを算出 sc = librosa.feature.spectral_centroid(y=y, n_fft=frame_length, hop_length=hop_length)[0] sc /= np.max(sc) # [0.0. 1.0]に正規化 # 最大値探索で無視する,先頭と末尾のデータ数を指定 n_ignore = 10 # サビらしさ特徴量時系列データ sc+rms より、 # 最もサビらしいインデックスを最大値探索で算出 # 念のため、2, 3番目に大きい値をとるインデックスも算出する indices = np.argsort((sc+rms)[n_ignore:-n_ignore])[::-1] + n_ignore # 最大値のみであれば、np.max((sc+rms)[n_ignore:-n_ignore]) でよい # 特徴量時系列データのインデックスと時間(秒)の対応関係 # 今回は、rmsとscはhop_lengthが同じなので以下でよい times = np.floor(librosa.times_like(sc, hop_length=hop_length, sr=sr)) # 推定サビ時刻(秒)を算出 chorus_estimated_time = times[indices[0]]
検証準備
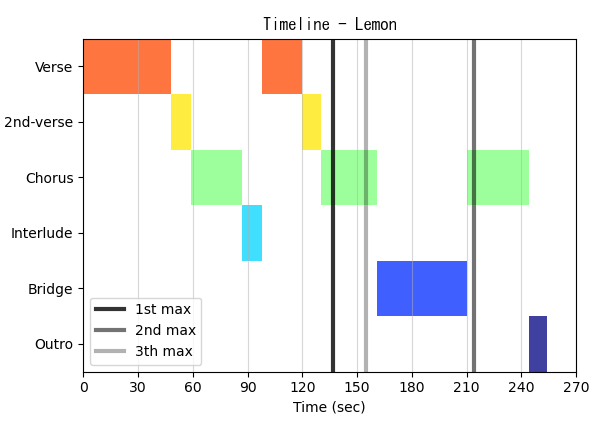
米津玄師の楽曲「Lemon」を使って検証します。
タイムラインのプロットは、以下の内容をベースに実装しました。
また、タイムラインをプロットするためのデータは、以下の自作アプリを使って作成しました。
動作検証結果
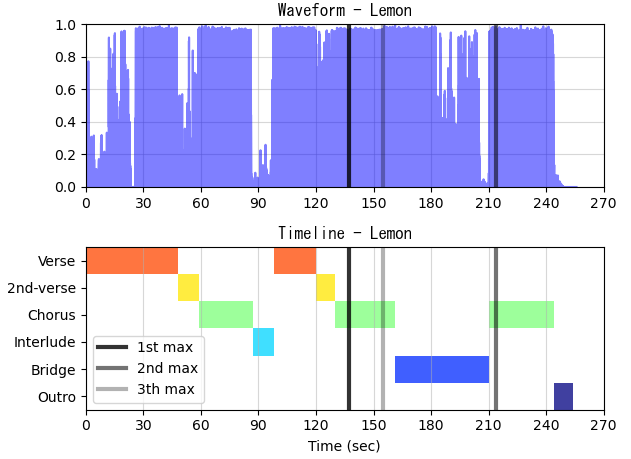
サビらしさ特徴量時系列データにおいて最大値を取る3か所の時刻を垂直線でプロットしました。
この結果から、最大値3箇所どれもサビ(Chorus)区間内であり、サビのおおよその位置を特定できたと考えることができます。
したがって、「サビ付近の30秒を切り出したい」といった用途であれば、このような手法だけでも十分かもしれません。
一方で、サビの区間の詳細、すなわち開始・終了時刻を細かく推定したい場合は、クラスタリング手法や、以下のような楽曲構成分析アルゴリズムと組み合わせて利用する必要があります。
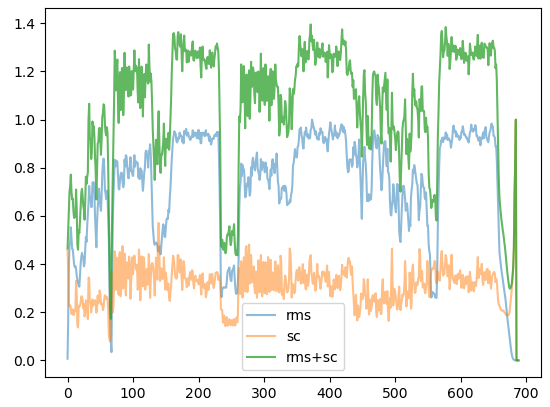
なお、RMSとスペクトル重心の算出結果は以下のようになっています。
今回の楽曲だとRMSだけでもよさそうです。
ただし、Aメロとサビの音量感が変わらないような楽曲ではスペクトル重心が効くと考えられます。
ただし、minmax正規化よりも標準化のようなスケーリングを適用したり、正規化では冒頭・末尾のデータを入れないほうが良さそうです
まとめ
LibROSAの音響特徴量を使ったサビ検出手法を実装・検証しました。
今回は単純な仮説を立てて、オーディオ信号から簡単に算出できるRMSとスペクトル重心を利用しました。
しかし、どちらもハイレベルな特徴量とは言えないので、周波数帯域や空間、時間変化量などに着目して特徴量を選定・追加するとよいと思います。
そしてそれら特徴量の組み合わせ方、すなわち重み付けをどうするかは人手で調整してもよいですし、機械学習を使う方法も考えられます。
また、このようなアルゴリズムの性能は、特徴量時系列データを算出する時の窓幅やホップ長、そして時系列データへの平滑化に強く依存します。
それらパラメタのチューニングは必要ですし、もしくはそれらを潜在変数として楽曲ごとに最適化することも考えられます。
なお、音響特徴量を使う手法は簡単でチューニングしやすいですが、例えばAメロとサビのコード進行の違いというような区間の音楽的な関係性を十分に利用できていません。
次回以降、クラスタリングや楽曲構成の分析手法を組み合わせた方法を紹介したいと思っています。