前回の記事では、Python向け楽器分離ライブラリ Spleeter の使い方を紹介しました。
具体的には、2-mixの楽曲ファイルを、ボーカルやベース、ドラムといったオーディオファイルに分離する方法を紹介しました。
Pythonでボーカル・ドラム・ベース・伴奏を抽出できる楽器分離ライブラリ Spleeter の使い方・デモ - Wizard Notes
今回は、和音・リズムの分析のような音楽信号分析処理での利用を想定したサンプルコードを紹介します。
1. Numpy配列の信号をSpleeterで処理
大量の楽曲を分析する際には、毎回オーディオファイルに書き出すと処理時間がかなりかかってしまいます。
そこで、Numpy配列をspleeterに与え、分離信号もNumpy配列として受け取ります。
import os import librosa from spleeter.separator import Separator class Spleeter(): def __init__( self, # vocals / bass / drums / other の4つのステムに分離 params_descriptor="spleeter:4stems" ): self.separator = Separator(params_descriptor) def run(self, x): return self.separator.separate(x) if __name__ == '__main__': filepath = "./Lemon.wav" #米津玄師 - Lemonを分析 sr = 44100 x, _ = librosa.load(filepath, sr=sr, mono=False) spleeter = Spleeter() y_dict = spleeter.run(x.T) y_vocals = y_dict['vocals'] y_drums = y_dict['drums'] y_bass = y_dict['bass'] y_other = y_dict['other']
ここで、Separator.separate()に与えるNumpy配列の形状は、(時間サンプル数, チャンネル数)とする必要があります。
一方で、LibROSAのload関数で読み込んだ信号は(チャンネル数,時間サンプル数) なので、転置する必要があります。
Separator.separate()の返り値(分離信号)は辞書形式であり、例えば4ステムのモデルでは上記コードのようなキーとなっています*1。
そして、y_dict['vocals']などそれぞれの分離信号としては (時間サンプル数, チャンネル数) のNumpy配列が格納されます。
なお、入力のNumpyがモノラルだった場合には複製してステレオ化されます。また、3チャネル以上ある場合が切り捨てられます。
2. 分離信号を使って音響特徴 (e.g. クロマベクトル) を算出
Spleeterのおかげで各トラックの音源が得られました。
それら分離信号を利用した分析例として、今回はメロディや和音を分析することを想定し、ボーカル、ベース、その他調波楽器のクロマベクトルを算出してみます。
具体的には y_dict['vocals'],y_dict['bass'],y_dict['other']からクロマベクトルを算出します。
ここで、クロマベクトルの算出には、音楽分析ライブラリLibROSAのlibrosa.feature.chroma_cqt()を使います。
y_dict["original"] = x.T
chroma_dict = {}
hop_length = 2048
for track_name, y in y_dict.items():
y = y.T
if track_name != 'drums':
# L, Rチャネルそれぞれで、クロマベクトルの時系列(クロマグラム)を算出
chroma = np.array([
librosa.feature.chroma_cqt(y=y[0], sr=sr, hop_length=hop_length),
librosa.feature.chroma_cqt(y=y[1], sr=sr, hop_length=hop_length)
])
chroma_dict[track_name] = chroma
3. 分離前のクロマベクトルと、分離信号のクロマベクトルを比較
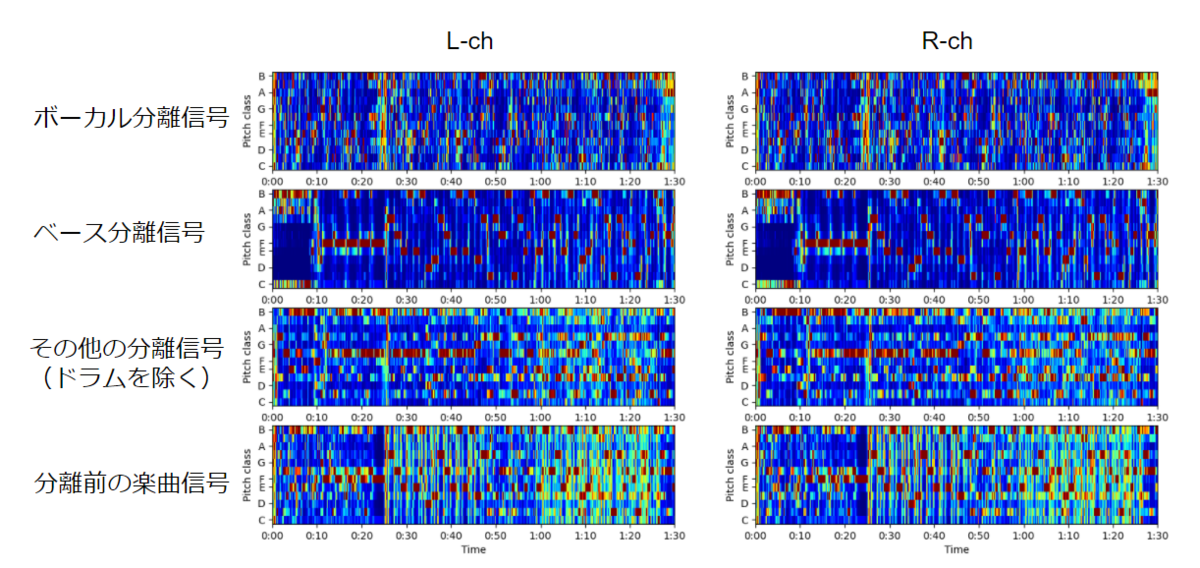
分離前と分離信号のクロマベクトルを比較してみました。
スペクトログラムのプロットを見て分かるように、分離前の信号だと特にサビ付近でクロマベクトルがスパースでないことが分かります。
これは、ドラムや各調波楽器トラックの成分が混ざってしまっているためと考えられます。
このままではメロディと和音とノイズの区別がつきにくいため音楽的分析が困難です。
一方で、分離信号のクロマベクトルは各ステムで異なる形状をしていることが分かります。
おそらく、ベースはベース音、ボーカルはメロディ、その他分離信号は和音に関する音高成分がちゃんと抽出できていると考えられます。
従って、Spleeterによる楽器分離によって音楽的役割の分析がしやすくなることが期待されます。
プロット用コード
n_stem = len(chroma_dict.keys()) + 1 n_plot = n_stem * 2 for k, (track_name, chroma) in enumerate(chroma_dict.items()): print(track_name) plt.subplot(n_stem, 2, 2*k+1) librosa.display.specshow(chroma[0], y_axis='chroma', x_axis='time', sr=sr, hop_length=hop_length, cmap="jet") plt.subplot(n_stem, 2, 2*k+2) librosa.display.specshow(chroma[1], y_axis='chroma', x_axis='time', sr=sr, hop_length=hop_length, cmap="jet") plt.show()
まとめ
楽器分離ライブラリ Spleeter にNumpy配列を与え、ボーカル・調波楽器を分離しクロマベクトルを算出してみました。
その結果、分離前信号では難しかった音楽の構成要素:メロディ、和音、リズムの分析が楽になる可能性を確認しました。
関連
*1:2stems, 5stemsの場合は、y_dict.keys()で確認してみてください