カラオケや補聴器のような音響システムでは、スピーカから出力した音が再びマイクへの入力としてフィードバックされることによる発振ハウリングが問題となります.
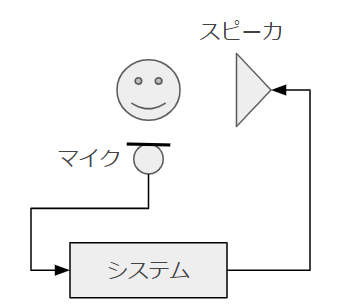
このハウリングを信号処理(適応フィルタ)によって除去する方法として、フィードバックキャンセラ(ハウリングキャンセラ)が知られています。
例えば、以下の書籍ではフィードバックキャンセラのC言語実装が掲載されています。
上記の書籍を参考に原理を整理しフィードバックキャンセラをPythonで実装してみましたので紹介します。
問題設定
フィードバックキャンセラの系は以下のブロック図で表されます.
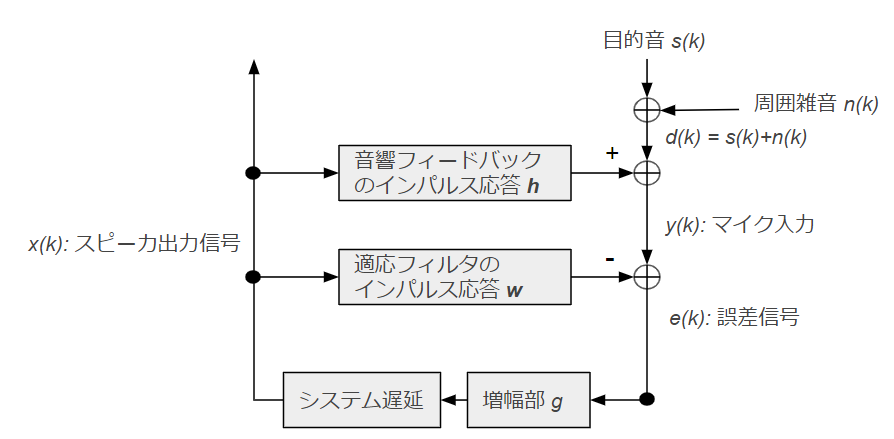
すなわち、外から入ってくる音 d(k) とフィードバック音 convolve(x(k), h) の混合信号 y(k) から、 誤差信号のパワーが最小となるようなフィルタ w を(逐次)推定する問題となります.
数理モデル・変数
フィルタ更新式導出のため、数理モデルを変数を整理します。 なお、ここでは簡単化のため x(k) のシステム遅延は無視します、
各時刻 k のマイク入力信号 d(k) は、以下のようになります。
h と x(k) 畳み込みをベクトル演算とするためのベクトル x(k) の作り方に注意してください。
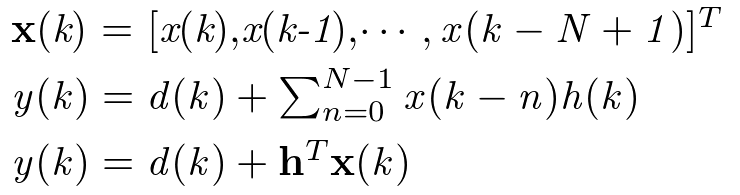
誤差信号、すなわちマイク入力信号 d(k) と適応フィルタ信号の減算は以下のように表されます。
すなわち、この誤差信号 e(k) が小さくなるような適応フィルタ w を見つける問題となります.
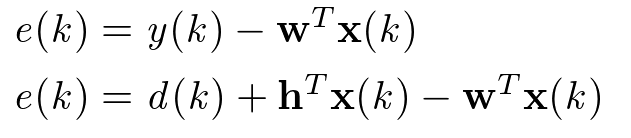
最適化
誤差信号の二乗誤差(パワー)の期待値(時間平均)を最小化することを考えます。
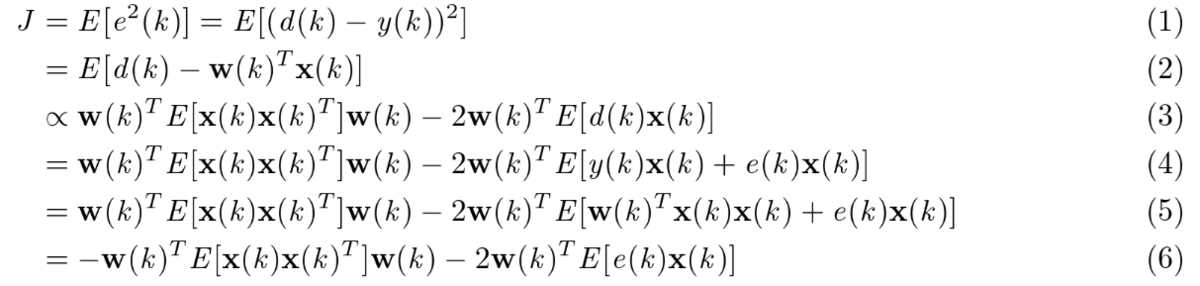
期待値を取ると演算量が多くなることを考え、瞬時値を使って最急降下法で適応フィルタ w を更新します。これは LMS (Least mean square) アルゴリズムと呼ばれています。
ここで、入力信号が非定常の場合、e(k)x(k)のパワーが変動するので適切なステップサイズ ν を設定するのが難しくなります.そこで、入力信号のパワーの時間平均で割ることでスケールを調整するようなステップサイズ μ を利用します.
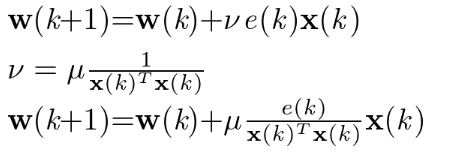
これが適応フィルタでよく利用されている正規化LMS (NLMS: Normalized LMS) アルゴリズムです.
詳細は参考文献をご覧ください。
Python 実装
全ソースコードは以下になります。
https://github.com/Kurene/audio-adaptive-filter/blob/main/feedback-cancellation.py
信号処理部だけ抜き出すと以下のようになっています。
なお、x(k) , x(k)はシステム遅延Mを考慮し、x(k-M), x(k-M)となっていることに注意してください。
for n in range(length): # フィードバック信号 x を生成 if n >= latency: x[n] = gain * e[n-latency] else: x[n] = 0.0 # 音響経路(スピーカ->マイク)の信号 xh と音源 d のマイク入力信号 y を生成 xh[n:n+n_ir_coef] += x[n] * h # 実環境では h は未知 y[n] = d[n] + xh[n] # 疑似音響経路の信号 xw とマイク入力信号 y の混合信号 e を生成 xw[n:n+n_ir_coef] += x[n] * w e[n] = y[n] - xw[n] # 係数更新 if n >= n_ir_coef: tmp_x_rev[:] = x[n-n_ir_coef:n][::-1] else: tmp_npad = n_ir_coef - n tmp_x_rev[:] = 0.0 tmp_x_rev[0:tmp_npad] = x[0:tmp_npad][::-1] norm_x = np.sum(tmp_x_rev ** 2) if norm_x > 0.00001 and CANCELLING: w[:] = w + mu * e[n] * tmp_x_rev / (norm_x + beta)
評価
シミュレーションでの評価を行いました。まず、音響フィードバックとして以下のようなインパルス応答を利用します。今回は簡易シミュレーションのため適当に作成しました。
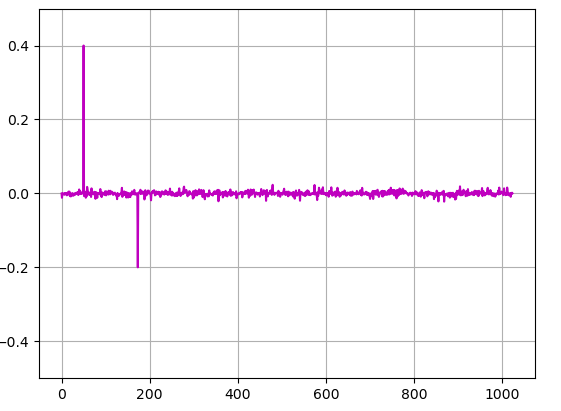
このIRを元に構築した音響フィードバックのある系に対して、適応フィルタを利用せずに単位インパルスをマイク入力信号とした時の結果が以下になります。この結果から出力信号のレイテンシーやフィードバックがシミュレーションできていることを確認できました。
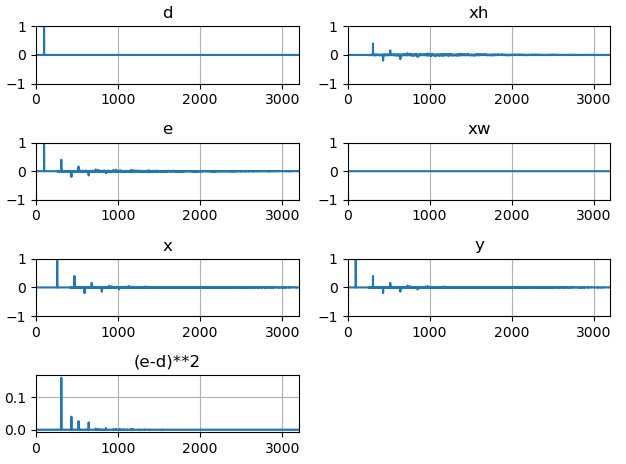
次に、librosaのサンプルデータ(音声)をマイク入力信号として与えてみます。まずは、適応フィルタを利用していない*1結果です。
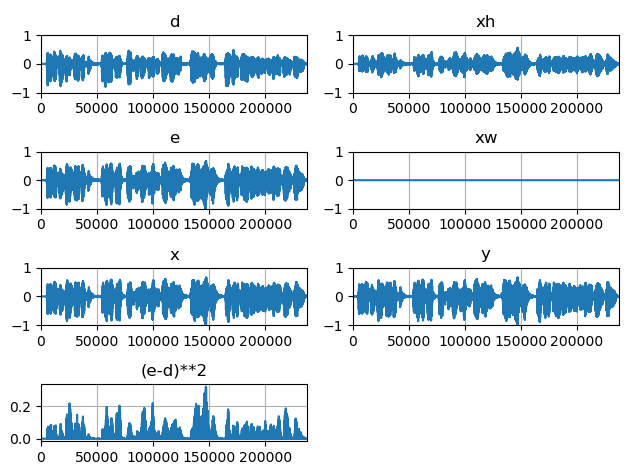
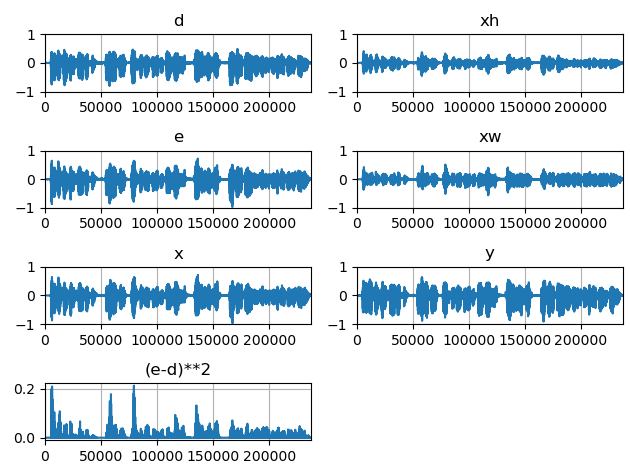
次に適応フィルタを学習・適用した結果です。先ほどの結果と比べて、誤差信号のパワー値(e-d)**2 が特に後半にかけて減っていることが確認できます。
なお、フィルタ係数の学習の様子をアニメーション化すると以下のようになりました。徐々に音響経路のインパルス応答に適応フィルタ係数が近づいていることが分かります。
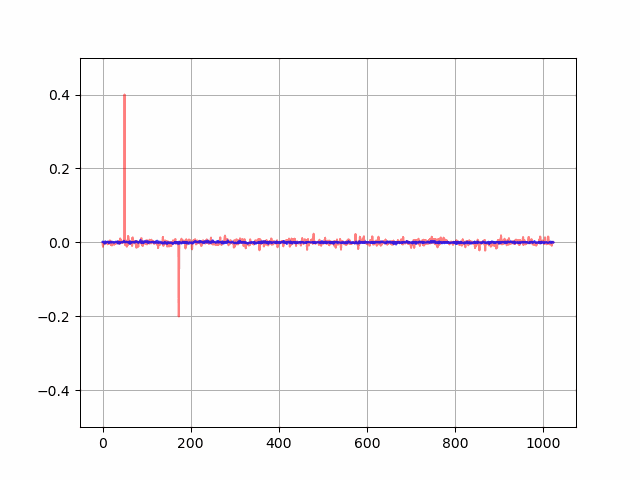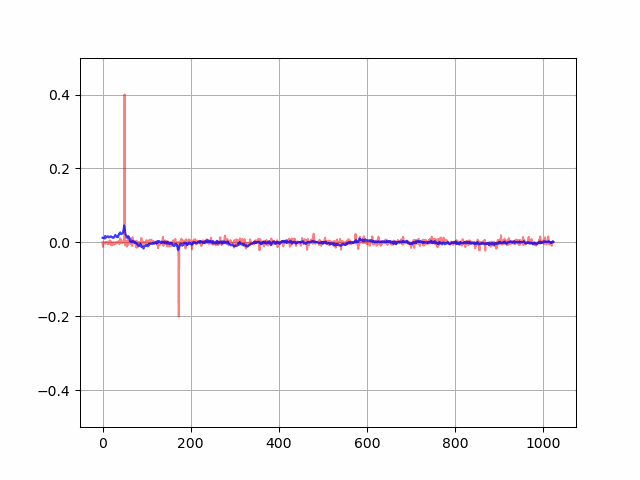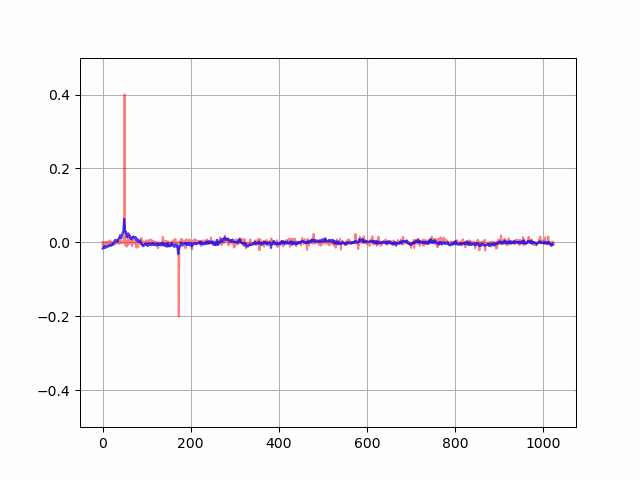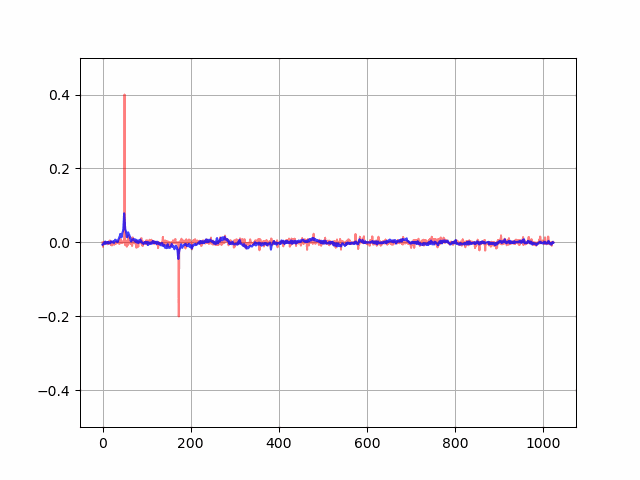
最後に、オリジナル/処理なし/フィードバックキャンセル処理ありの音声データを作成したので掲載します。
まとめ
フィードバックキャンセラのPython実装を行い、動作テストと適応フィルタの効果を確認しました。
実用上では、入力信号dとフィードバック信号xに相関があることでフィルタ係数の推定に悪影響があることが知られています。そのため、対策としてシステム遅延を長めに設定したり、相関を予め考慮した改良手法が提案されています。
また、実用的なフィルタ係数算出方法としてフィルタ係数に対する正則化を加えたNLSMアルゴリズムもありますので、ご興味がある方は調べてみてみてください。
参考文献
- 工藤 憲昌, 釜谷 博行, 田所 嘉昭, 補聴器用ハウリングキャンセラに関する検討, 八戸工業高等専門学校紀要, 2021, 55 巻, p. 59-62, 公開日 2021/05/08
- 電子情報通信学会 知識の森 1 群(信号・システム)-- 9 編(ディジタル信号処理)3 章 適応信号処理
- 電子情報通信学会 知識の森 2 群 - 6 編 - 5 章 5-2 音声を入力とする音響エコーにおける適応フィルタ
- 音声信号処理の基礎理論(後編) ―― 線形フィルタ,適応アルゴリズム,周波数領域の処理|Tech Village (テックビレッジ) / CQ出版株式会社
*1:適応フィルタwの全ての係数が0の場合